Kinų GLM-5.2: atvirojo kodo modelis, kuris prilygsta rinkos geriausiems
Data: 2026 m. birželio 17 d.
Z.AI išleido GLM-5.2 su 1 milijono tokenų kontekstu – atvirojo kodo modelis, kuris ilgų kodavimo užduočių benchmarkuose prilygsta Claude Opus 4.8.
Trumpai (TL;DR):
Z.AI išleido GLM-5.2 su MIT licencija ir 1 milijono tokenų kontekstu – stipriausias atvirojo kodo modelis ilgų kodavimo užduočių kategorijoje.
FrontierSWE benchmarke atsilieka nuo Claude Opus 4.8 tik 1%, aplenkia GPT-5.5 ir Opus 4.7; architektūrine naujove IndexShare sumažina skaičiavimų kiekį 2,9 karto esant 1M kontekstui.
MIT licencija be regioninių apribojimų reiškia, kad bet kas – įskaitant Europos įmones – gali šį modelį paleisti be teisinių spąstų, kuriuos kartais sukuria kitos kinų kompanijų licencijos.
„Atvirasis kodas" AI pasaulyje jau seniai reiškia skirtingus dalykus skirtingiems žmonėms. Vieni išleidžia svorius su komerciniais apribojimais, kiti su geografiniais filtrais, dar kiti tik apsimeta atvirais. „Z.AI" su GLM-5.2 padarė paprastai: MIT licencija, be regioninių ribų, Ollama palaikymas iš karto. Teoriškai tai turėtų būti norma. Praktikoje – retenybė.
1 milijonas tokenų – ir tai reikia suprasti tiesiogiai
Paskelbti 1M tokenų kontekstą dabar nesunku. Problema kitokia: kai agentų darbo eigos pailgėja ir komplikuojasi, daugelio modelių kokybė tiesiog suprastėja iki minimumo.
„Z.AI" teigia, kad GLM-5.2 buvo specialiai treniruotas tokiems scenarijams – didelės apimties kodo rašymui, automatizuotiems tyrimams, našumo optimizavimui ir sudėtingam derinimui. Skamba kaip rinkodara, kol nepažiūri į benchmarkus.
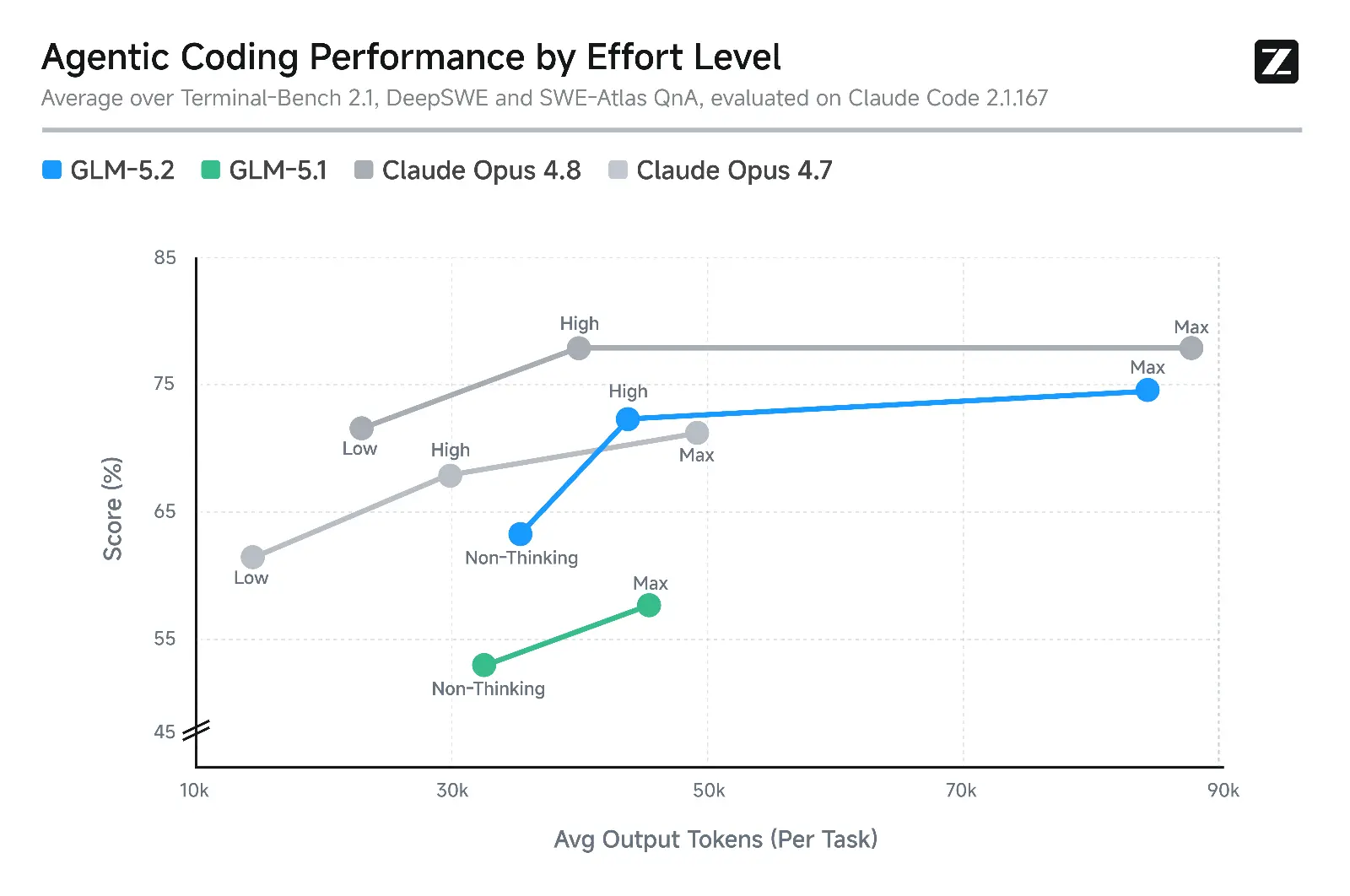
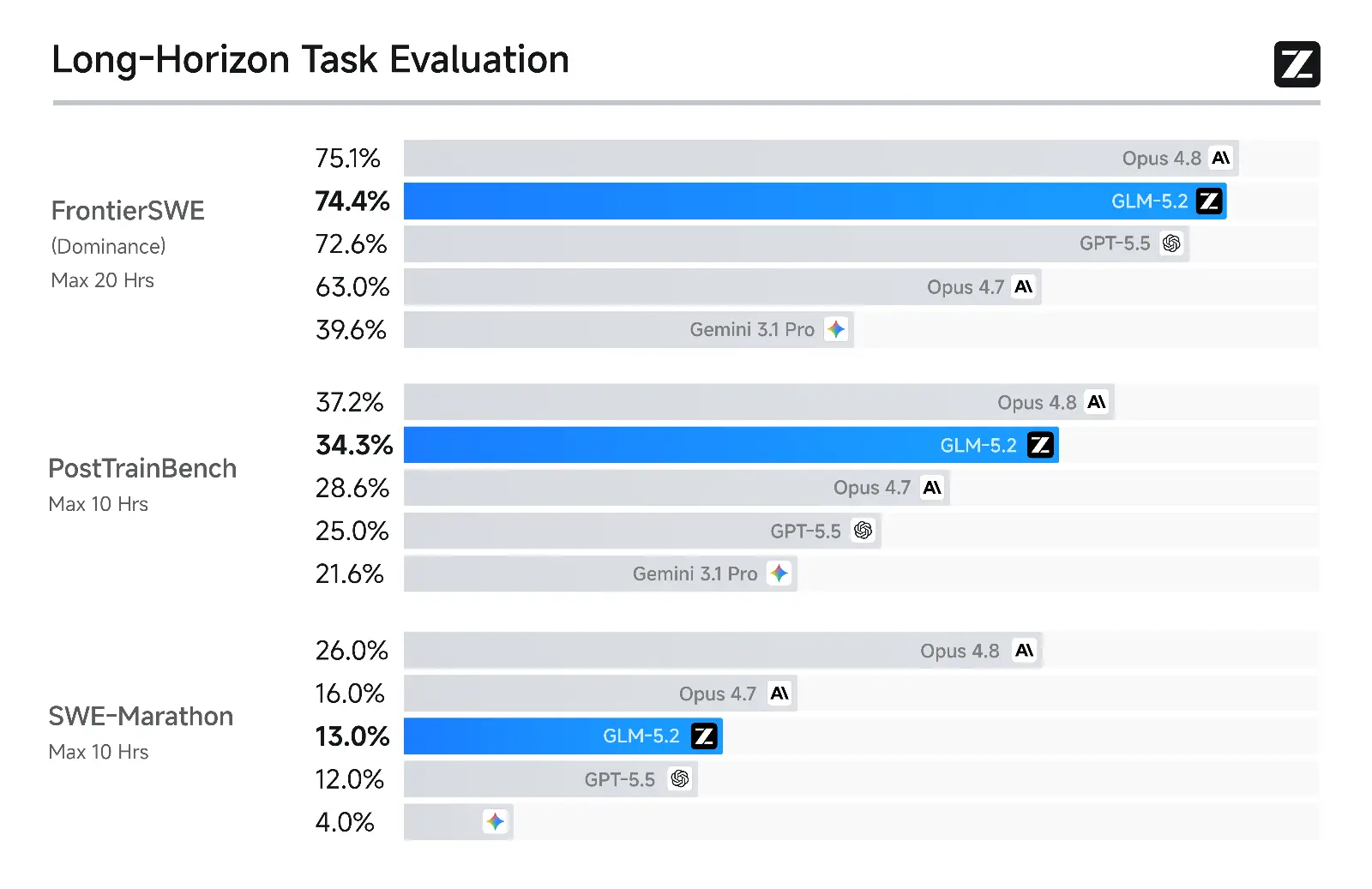
FrontierSWE matuoja, ar modelis gali savarankiškai įgyvendinti atviruosius techninius projektus per kelias ar keliasdešimt valandų. GLM-5.2 atsilieka nuo Claude Opus 4.8 vos 1%, aplenkia GPT-5.5 taip pat 1% ir Opus 4.7 net 11%. PostTrainBench panaudojimo scenarijuje kiekvienas agentas gauna H100 GPU ir optimizuoja mažus modelius per post-training (treniravimą po pradinio mokymo) procesą. Čia GLM-5.2 aplenkia ir GPT-5.5, ir Opus 4.7, nusileidžia tik Opus 4.8.
SWE-Marathon – pats ilgiausio horizonto testas, apimantis kompiliatorių kūrimą, branduolių optimizavimą ir gamybinio lygio paslaugų kūrimą. Šiame teste GLM-5.2 atsilieka nuo Opus 4.8 jau 13%. Kažkur riba vis tiek yra.
Bet svarbu tai: visuose trijuose benchmarkuose GLM-5.2 yra geriausias atvirojo kodo modelis. Ne tarp kinų. Apskritai.
Architektūrinė gudrybė, kurią verta suprasti
Ilgų kontekstų problema – ne tik atminties klausimas. Kuo ilgesnis kontekstas, tuo daugiau skaičiavimų reikia kiekvienam tokeniui. Tradiciniai sparse attention (retosios dėmesio) mechanizmai šį klausimą sprendžia iš dalies, bet turi savo kainą.
„Z.AI" pristatė IndexShare: tas pats indeksuotojas naudojamas kas keturiems retosios dėmesio sluoksniams. Rezultatas – esant 1M tokenų kontekstui skaičiavimų kiekis vienam tokeniui sumažėja 2,9 karto. Tai reikšmingas skaičius, nes debesijos kaštai skaičiuojami būtent tokiais vienetais.
Papildomai patobulinta MTP (Multi-Token Prediction) sluoksnio logika spekuliatyviam dekodavimui: priėmimo ilgis išaugo iki 20%. Praktiškai tai reiškia greitesnį teksto generavimą, nes modelis tiksliau nuspėja kelis tokenius iš eilės.
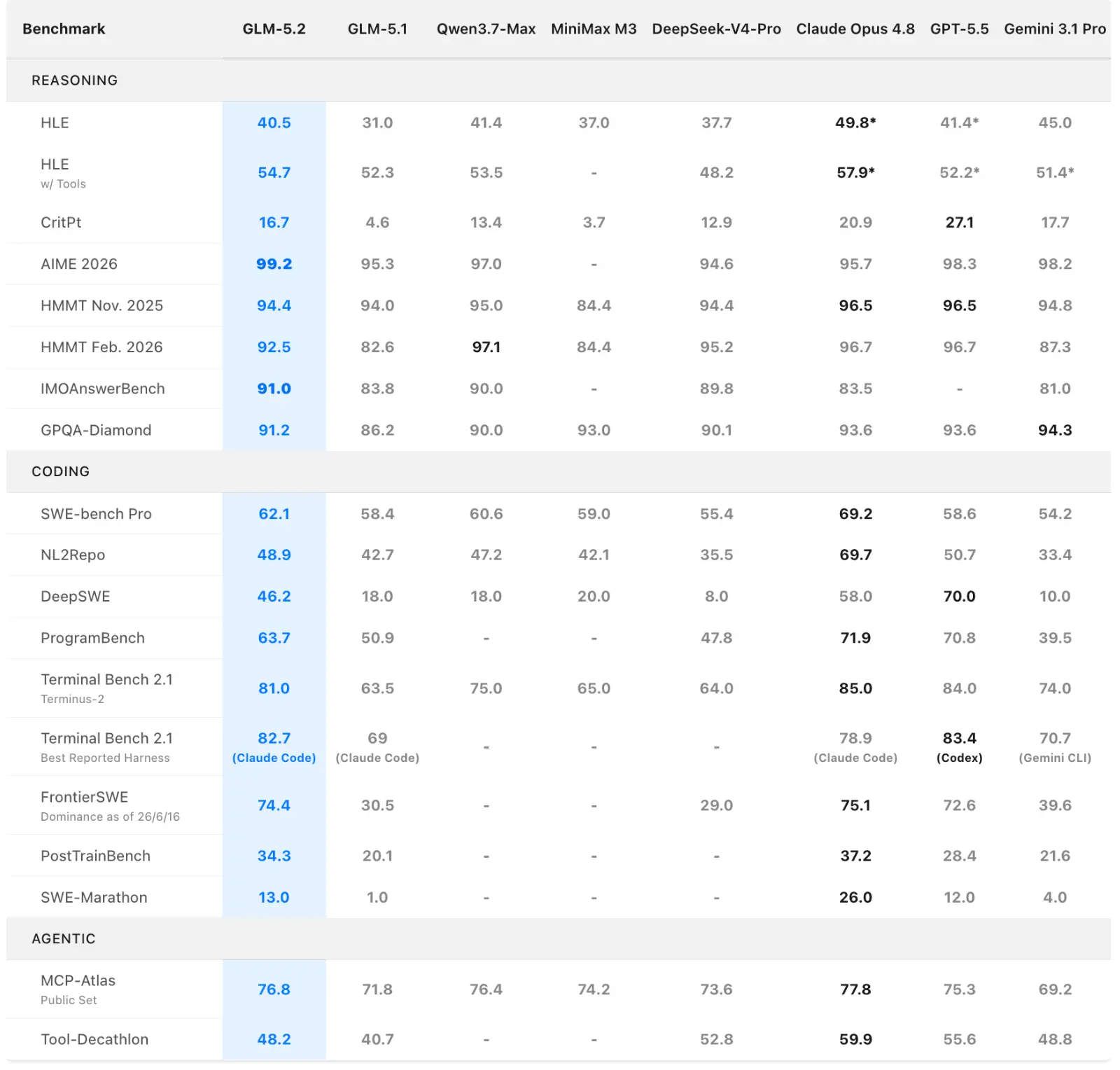
Standartiniuose kodavimo benchmarkuose Terminal-Bench 2.1 rezultatas – 81,0 taško, kai Opus 4.8 surinka 85,0. SWE-bench Pro: 62,1, kai ankstesnis GLM-5.1 surinko 58,4. Pažanga yra.
MIT licencija ir ko ji iš tikrųjų verta
Kinų AI kompanijų atvirojo kodo istorija nevienoda. Kai kurie modeliai buvo išleisti su licencijomis, draudžiančiomis naudojimą tam tikrose šalyse arba reikalavusiais atskiro komercinio susitarimo. DeepSeek sukėlė entuziazmą, bet jo licencija vis tiek turėjo sąlygų, dėl kurių Europos teisiniai skyriai nervingai kraipė galvas.
MIT licencija kitokia. Ji leidžia naudoti, modifikuoti ir platinti be beveik jokių apribojimų. Jei Lietuvos programuotojas nori paleisti GLM-5.2 savo serveriuose, integruoti į komercinį produktą ar tiesiog eksperimentuoti – teisiškai viskas tvarkoje. Tokio paprastumo kaina mokama kitur: reikia duomenų ir infrastruktūros.
Ollama palaikymas iš karto reiškia, kad modelį galima atsisiųsti ir paleisti viena komanda. Vilniuje ar Kaune, su tinkamu GPU, tai dabar realu net vidutinio dydžio komandai.
Kur atsiranda įtampa
Visas šis taškelių lyginimas turi kontekstą. „Z.AI" priklauso „ZhipuAI" orbitai – universitetinės kilmės kinų kompanijai, kuri sparčiai auga. Modelio svoriai prieinami viešai, bet treniravimo duomenys – ne. Tai ne MIT licencijos problema, bet klausimas, kurį rimtas vartotojas turėtų sau užduoti.
FrontierSWE ir SWE-Marathon geresni už daugelį kitų benchmarkų, nes matuoja realias inžinerines situacijas, o ne abstrakčius galvosūkius. Bet tarp „gerai atrodau benchmarke" ir „stabiliai veikiu šešis mėnesius gamyboje" visada yra tarpas, kurį galima sužinoti tik vienu būdu.
Ponas Obuolys sako:
Kinai išleido modelį su MIT licencija, kuris beveik lygiomis bėga su Claude Opus 4.8 – modeliu, už kurio API prieigą „Anthropic" ima rimtus pinigus. Ir padaro tai atvirai, be geografinių filtrų. Tai yra žinia.
Aišku, ko trūksta, galima rasti. 13% atsilikimas SWE-Marathon benchmarke tikras. Treniravimo duomenys neskaidrūs – irgi faktas. Bet jei euroskeptiškas technologijų vadovas Vilniuje šiandien ieško, kuo pakeisti brangiausius uždaro kodo modelius vidaus infrastruktūroje, jis tikrai žiūri į šią kryptį.
Įdomiausia detalė ne benchmarkai, o IndexShare architektūra. 2,9 karto mažiau skaičiavimų 1M kontekstui – tai inžinerinis sprendimas, kurį kiti dabar studijuos ir kopijuos. Tokia atvirojo kodo logika: išleidi, kiti paima geriausią dalį ir eina toliau. „Z.AI" turbūt tai žino. Ir vis tiek paleido.
Šaltiniai: „Z.AI" oficialus tinklaraštis (z.ai/blog/glm-5.2), „The Decoder", „VentureBeat", „Ollama" biblioteka.